Building Pipeline For Data Harvesting With Apache Airflow

Search for a command to run...
No comments yet. Be the first to comment.
In this article, we explored how to deploy a graph database on AWS using Amazon Neptune, how to load some data into the database, and how to query those data. The graph data model is rapidly becoming the ideal way for modeling datasets that are highl...

Using SQL to predict telecoms customer churn based on customer activity data (95+% accuracy).

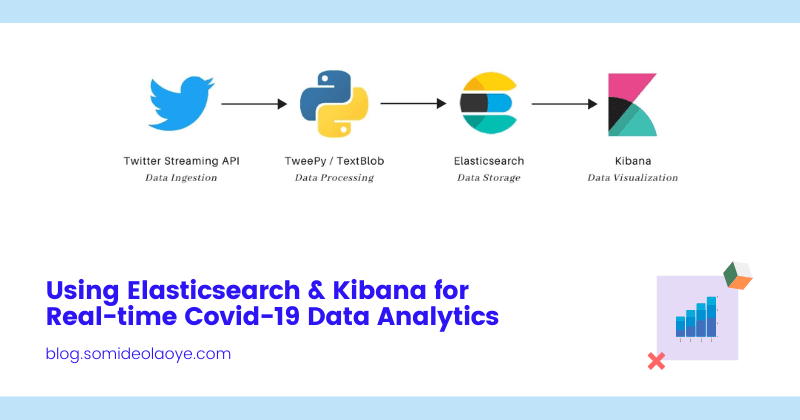
Analyzing data in real-time gives us the opportunity to derive important insights from data and respond to events as they occur. More than any other topic, COVID-19 was the most discussed topic globally in 2020. Since the beginning of the outbreak,...
FastAPI is a modern and fast Python web framework for building backend applications. FastAPI comes with support for API documentation powered by Swagger, security modules, and type checking to ensure correctness in code. Why choose FastAPI over othe...

Apache Airflow is an open-source workflow automation tool that can be used to programmatically author, schedule, and monitor data processing pipelines. Airflow originated at Airbnb in 2014 and became a top-level open-source project under Apache Software Foundation in January 2019.
Since its inception, Apache Airflow has quickly become the de-facto standard for workflow orchestration. Now, Airflow is in use at more than 200 organizations, including Adobe, Airbnb, Etsy, Google, Lyft, NYC City Planning, Paypal, Reddit, Square, Twitter, and United Airlines, among others.
Apart from its ease to use and the growing community of contributors, what has made Airflow become so popular today is its ability to easily integrate with commonly used 3rd party tools such as BigQuery, AWS S3, Docker, Apache Hadoop HDFS, Apache Hive, Kubernetes, MySQL, Postgres, Apache Zeppelin, and many more.
Before digging deep on how to build data pipelines with Airflow, there are 3 basic concepts of Airflow that we need to understand. The combination of any of these basic concepts forms the building blocks of workflow automation with Airflow.
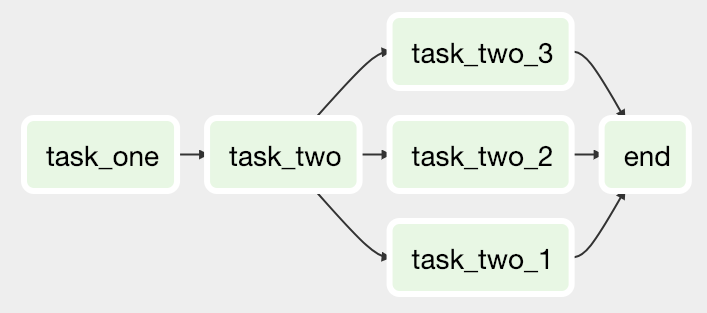
Directed Acyclic Graph (DAG) is a collection of all the tasks you want to run, organized in a way that reflects their relationships and dependencies. We can also see it as a series of protocol that defines the order of how the tasks should run (E.g. Run Task_A after Task_B etc.)
DAGs are defined at the beginning of the pipeline before the tasks. They should have a unique ID (dag_id) and default arguments (default_args). The below code is a simple declaration of an Airflow DAG.
from datetime import datetime
from airflow import DAG
default_args = {
"owner": "airflow",
"start_date": datetime(2020, 12, 12),
"schedule_interval": "@daily"
}
dag = DAG('sample_dag', default_args = default_args)
An operator represents a single, ideally idempotent, task. Operators know how to perform a specific task and have the tools to do it. Airflow provides operators for many common tasks and you can also create your own custom operator. Commonly used operators include;
PythonOperator used to run python functions.BashOperator used to run bash commands.PostgresOperator used to run SQL commands on Postgres.EmailOperator used to send emails.SimpleHttpOperator used to make HTTP requests.A task is a job that is done by an operator. Each task is an implementation of an Operator and it is represented as a node within the DAG. The task_id parameter needs to be unique within the DAG that it was instantiated.
# task that runs a bash command
bash_task = BashOperator(
task_id='print_hello_world',
bash_command='echo "Hello World!"',
dag=dag
)
It's important to mention some other Airflow concepts that would be used in the pipeline that we are going to build.
xcom_push() and xcom_pull() functionalities.Let's build a simple Airflow data pipeline that harvests the data of new earthquake events with a magnitude of 5.0 and above from the USGS Earthquake API on a daily basis.
The data pipeline execution would be broken down into 4 different tasks:
The task objective was to create a table in our Postgres database if none exists. As shown below, the task uses the PostgresOperator() to create a table with the Postgres database. The Postgres database connection parameter was referenced using the postgres_conn_id value.
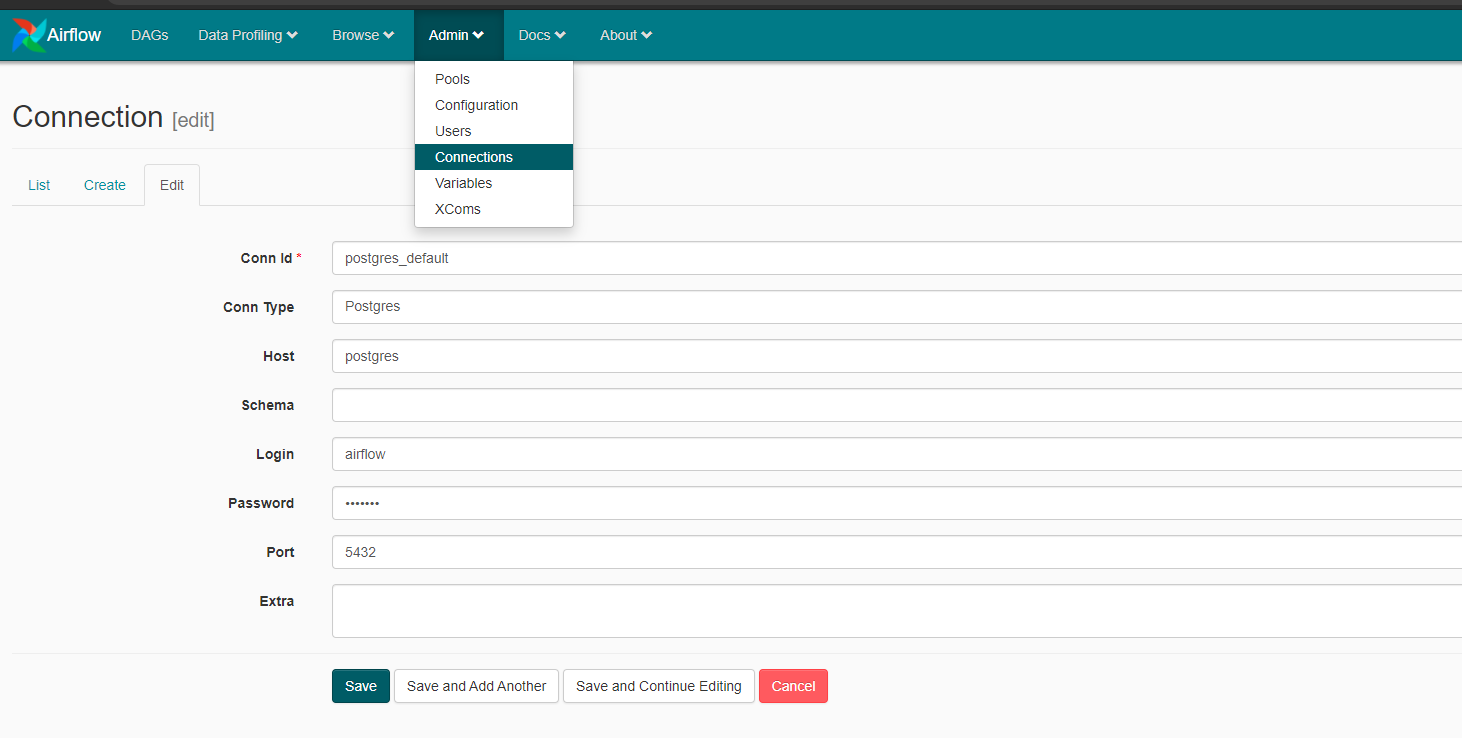
Airflow connection with Postgres is defined in the Airflow UI as shown in the image below.
The database name was stored in Airflow as a variable and was reference using the Variable.get("USGS_DB_NAME") function. The images show the defined variables for this exercise.
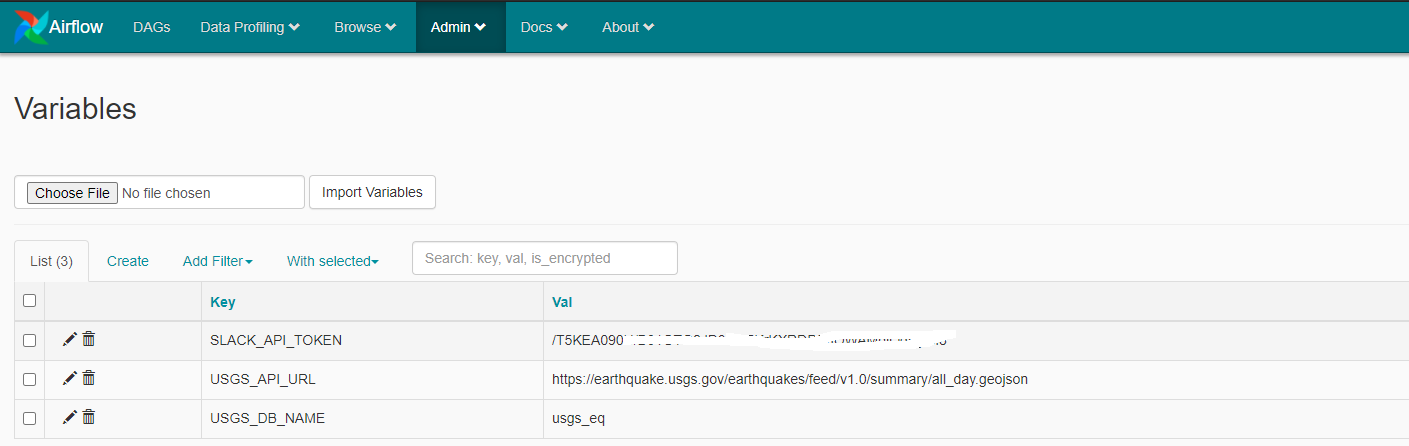
This task is responsible for making an API request. The task uses the PythonOperator() to call the defined python function named get_events_from_api(). The function would return a list of events with a magnitude greater than 5.0 and pass the returned data into the next task using XCom. The USGS API endpoint was stored in Airflow as a variable and was reference using the Variable.get("USGS_API_URL") function.
Just like the previous task explained, this task makes use of the PythonOperator() to run the Python function save_events_to_db(). This function is responsible for storing the received events from our API requests into our Postgres database. For this task, the PostgresHook() was used to connect Postgres. The function also uses XCom to retrieve the data that was passed from the previous task.
The final task is responsible for posting messages on Slack after the three previous tasks are completed. It uses the SlackWebhookOperator() with Slacks API webhook credentials to execute the task.
For this purpose, you need to create a Slack App. After creating the application, activate the Incoming Webhook function for the application and use the webhook credential to create a connection in Airflow slack_conn that would be able to communicate with Slack.
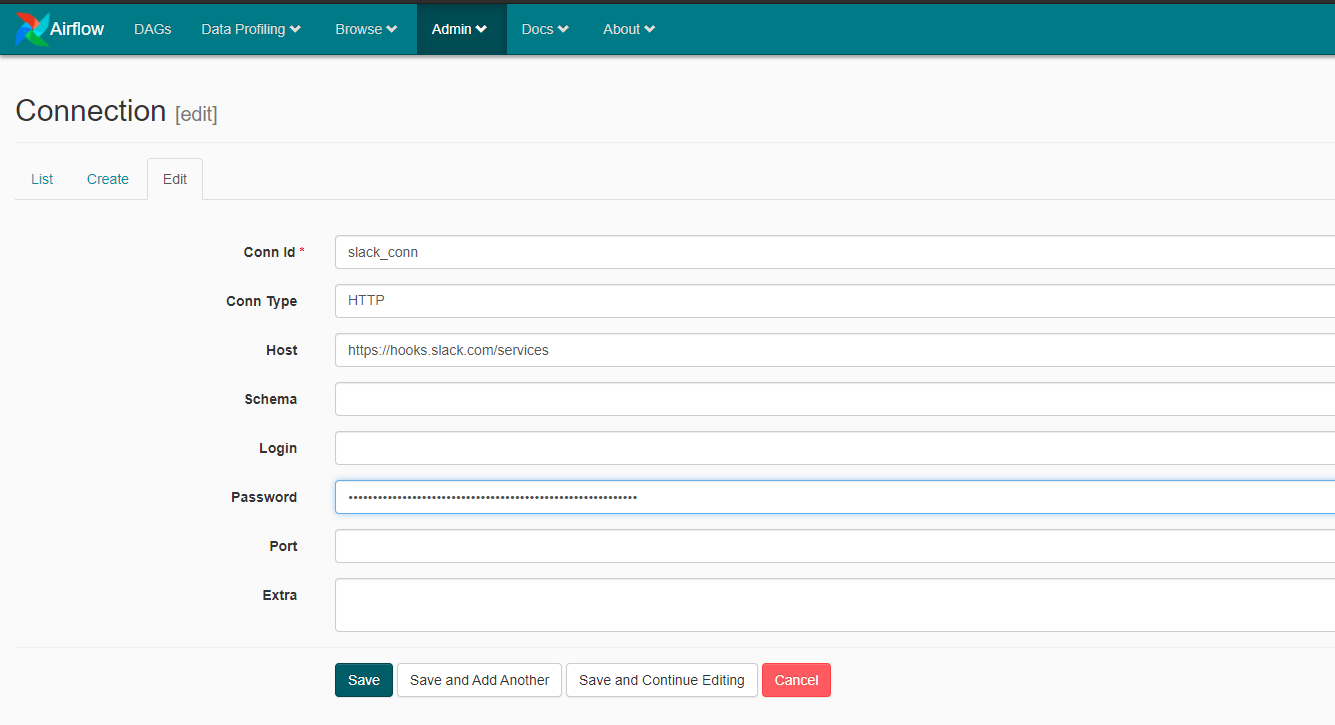
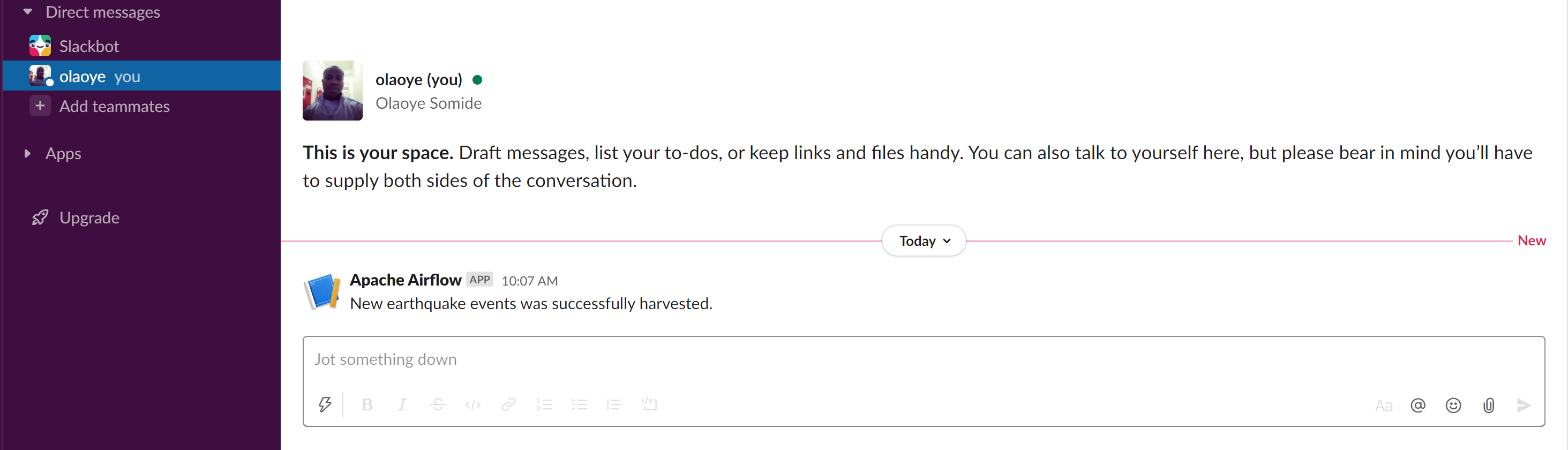
The task is then able to send a message to Slack when executed.
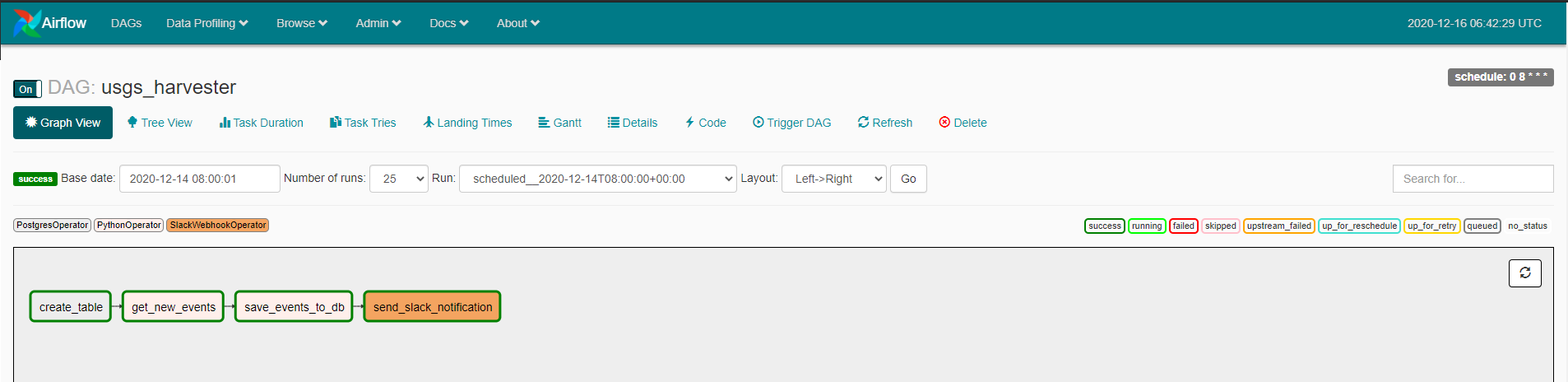
The Airflow DAG is scheduled to run daily at 8 AM. All the four tasks are going to run in series (i.e. one after the other) as some of the tasks require input from the previous task to run successfully.
# execute pipeline tasks in series
task_one >> task_two >> task_three >> task_four
From Airflow's UI you can activate or deactivate the pipeline execution by toggling ON/OFF the DAG. You can also monitor the status of your pipeline execution and check the logs in cases of failure.
Airflow is entirely free to use and completely customizable but requires in-depth coding knowledge to implement. It is designed to make handling large and complex data workflows easier.
To avoid the complexity of installing Airflow on local machines or VMs, you can also run your Airflow DAGs on managed Apache Airflow platforms like Cloud Composer on Google Cloud or Amazon Managed Workflows for Apache Airflow. These two platforms give you the flexibility to scale your resources as needed and only pay for what you use.
The full source code for this project is available on Github.